MuSoHu


[Paper] [Video] [Dataset] [Code]
About
Humans are well-adept at navigating public spaces shared with others, where current autonomous mobile robots still struggle: while safely and efficiently reaching their goals, humans communicate their intentions and conform to unwritten social norms on a daily basis; conversely, robots become clumsy in those daily social scenarios, getting stuck in dense crowds, surprising nearby pedestrians, or even causing collisions. While recent research on robot learning has shown promises in data-driven social robot navigation, good-quality training data is still difficult to acquire through either trial and error or expert demonstrations.
In this work, we propose to utilize the body of rich, widely available, social human navigation data in many natural human-inhabited public spaces for robots to learn similar, human-like, socially compliant navigation behaviors. To be specific, we design an open-source egocentric data collection sensor suite wearable by walking humans to provide multi-modal robot perception data; we collect a large-scale (∼100 km, 20 hours, 300 trials, 13 humans) dataset in a variety of public spaces which contain numerous natural social navigation interactions; we analyze our dataset and demonstrate that robots can learn socially compliant navigation from our dataset.

Multi-Modal Sensor Suite
We design and make publicly available a data collection device, which is wearable by a human walking in public spaces and provides multi-modal perceptual streams that are commonly available on mobile robot platforms. We also process the raw data to extract human navigation behaviors, i.e., the paths and actions taken by the human demonstrator to navigate through social spaces. We provide the following sensors in our multi-model sensor suite:
- 3D LiDAR (Velodyne Puck)
- Stereo and Depth Camera (Stereolabs ZED 2)
- IMU (Stereolabs ZED 2)
- Odometry / Actions (Online Processing Script)
- 360-degree Camera (Kodak Pixpro Orbit360 4K)
- Microphone Array (Seeed Studio ReSpeaker Mic Array v2.0)




Data Collection in the Wild
An initial batch of MuSoHu is collected on the George Mason University campus and in the Washington DC metropolitan area. Data collection is still ongoing and we will work with external collaborators to expand MuSoHu with more social human navigation data collected worldwide.
To collect multi-modal, socially compliant, human-level navigation demonstrations to learn future robot navigation, x human demonstrators wear the sensor suite helmet and navigate to a predefined goal in public spaces in a socially compliant manner. We choose navigation scenarios with frequent social interactions. Social human navigation data is collected in various indoor and outdoor environments at different time periods (e.g., after class or during weekends). The sensor suite’s superior portability (i.e., only a helmet and a laptop) also allows us to record portions of MuSoHu in other settings in the Washington DC Metropolitan Area, including Fairfax, Arlington, and Springfield in Virginia and the National Mall in DC. Notably, for a trajectory at a certain location at the same time period, in most cases, we record three trials to capture three navigation contexts, i.e., casual, neutral, and rush, in which walking speed and safety distance from others may vary, in order to encourage different social navigation interactions based on different contexts. We intend such context awareness in MuSoHu to be useful for future studies on context-aware social navigation, e.g., social compliance when facing someone who is about to be late for a class is different than that when facing someone who is taking a casual afternoon stroll in the park.
For each trajectory, all sensor data are collected using the Robot Operating System (ROS) Bag functionality, except the 360° camera, which does not allow data streaming of both built-in cameras to provide spherical 360° view to ROS. Therefore, we store the 360° video on an SD card and provide synchronization using a movie clapboard.

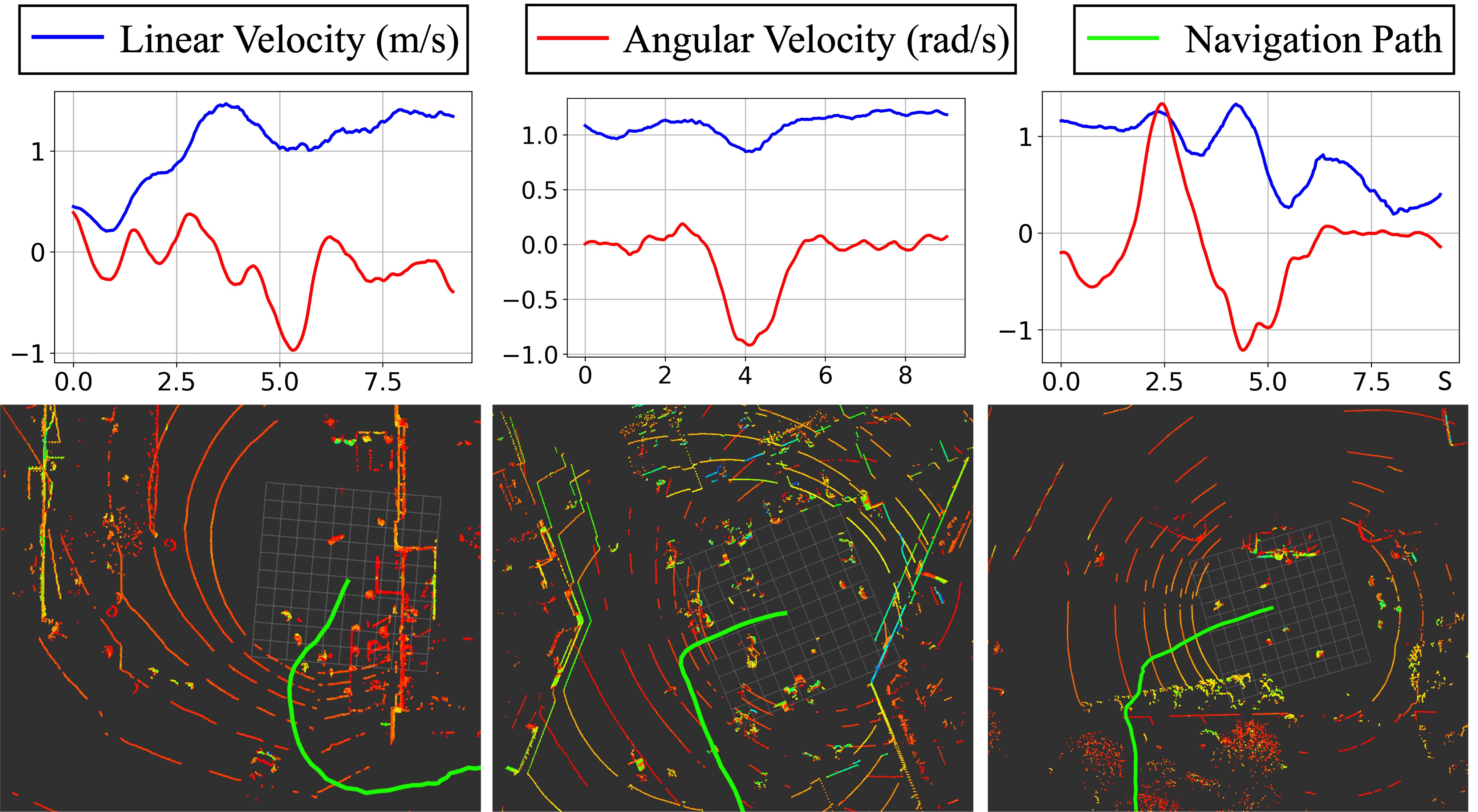
The following figure shows corresponding linear and angular velocities (filtered by Savitzky-Golay filter to smooth out high frequency noises caused by walking gait) and navigation path taken by the human demonstrator in the three scenarios above. In the first scenario, the demonstrator navigates around a right corner and avoids an upcoming family; in the second scenario, the demonstrator makes a 90° right-hand turn, while avoiding people in an indoor food court; in the third scenario, the demonstrator dodges (right-left-right) a dense crowd during a right-hand turn. Both linear and angular velocities and navigation path provide learning signals for mobile robots.
Anticipated Use Cases
We posit the MuSoHu dataset will be useful for the following use cases in future research.
Learning Social Robot Navigation
The primary purpose of MuSoHu is to provide a large corpus of training data for mobile robots to learn socially compliant navigation behaviors. As we demonstrate in our preliminary experiments, robot navigation behaviors similar to the human behaviors in MuSoHu can be learned end-to-end using Behavior Cloning. Other imitation learning methods, such as IRL, can utilize MuSoHu to learn a socially compliant cost function for downstream navigation planners.
The replicability of our sensor suite makes collecting social human navigation data very easy. We intend the sensor suite to be replicated by different research groups to collect data in different countries worldwide. An even larger and also more diverse corpus of data opens up orthogonal research directions that are not currently possible. For example, new social robot navigation systems can be developed that are culturally dependent, i.e., the way a mobile robot moves can be fit into different culture contexts. For example, imagine a contact-tolerant culture where pedestrians are comfortable with walking very closely to each other vs. a contact-averse culture where people prefer to keep distance.
Imitation Learning with Various Constraints
One potential challenge, in other words, opportunity for future research, is how to address the difference in human and robot navigation. Human navigation is based on legged locomotion, while most mobile robots are wheeled or tracked. Different motion morphologies caused by such an embodiment mismatch may require extra care to be taken during learning. Transfer learning techniques [24] may provide one promising avenue to leverage the full potential of MuSoHu. In addition to the different motion morphologies, despite our choice of sensor modalities to align with robot perception, viewpoint mismatch still exists: to avoid occluding the 3D LiDAR view, it is mounted on top of the helmet, which is higher than most robots’ LiDAR position; all perceptual data are subject to the effect of walking gait cycles, e.g., the cyclic motion along the vertical axis, which does not exist for most mobile robots. Therefore, imitation learning from observation techniques need to be investigated to address the perceptual mismatch between MuSoHu and mobile robots.
Studying Social Human and Robot Navigation
One question being debated frequently is should roboticists build robots to navigate in public spaces in the same way as humans? Our MuSoHu dataset, along with its future extensions in different countries worldwide, and SCAND, provide a way to investigate related problems. Assuming the navigation behaviors in MuSoHu and SCAND are the optimal way of human and robot social navigation in public spaces respectively, we can analyze both datasets to see whether the human and robot behaviors are the same, similar, or completely different. Another way is to build social robot navigation systems with the data in MuSoHu and SCAND and evaluate the learned social navigation behaviors with standardized protocols and metrics to see wheter there is any difference between the two and if yes which way is preferred by people that interact with the robots.
Real-to-Sim Transfer for Social Navigation
Creating high-fidelity social navigation simulation environments has been a focus of social robot navigation researchers. A realistic simulator that can induce real-world human-robot social interactions that conform with the underlying unwritten social norms will facilitate social robot navigation research on multiple fronts, such as reinforcement learning based on simulated trial and error, large scale validation and evaluation of new social navigation systems before their real-world deployment, and objective and repeatable benchmark and comparison among multiple social navigation systems. However, existing social navigation simulators rely on simplified human-robot interaction models, e.g., the Social Force Model or ORCA. Such a sim-to-real gap may cause problems when the navigation systems learned, evaluated, or compared in simulation are deployed in the real world.
The MuSohu dataset provides another alternative and promising avenue toward shrinking such a sim-to-real gap through real-to-sim transfer to improve social navigation simulation. The data collected in the wild in MuSoHu enable researchers to synthesize natural, real-world, human-robot social navigation interactions in simulation. Approaches can be developed to learn such interaction models from the natural interactions in MuSoHu, which can be used to control simulated agents, robots or humans, in a high-fidelity simulator.
Investigating Robot Morphology for Social Navigation
Human-human social navigation interactions embody a large set of interaction modalities, which are frequently present in MuSoHu. For example, in addition to avoiding other humans as moving obstacles, humans use gaze, head movement, and body posture to communicate navigation intentions in crowded spaces; they use body or natural language to express their navigation mindset or context (e.g., they are in a rush and apologize for being less polite). Most current mobile robots, however, do not possess such capabilities to communicate their navigation intentions and contexts in an efficient manner. Analyzing the human-human social navigation interaction modalities in MuSoHu will shed light on what other robot morphology may be useful to facilitate efficient social navigation, such as adding a robot head with gaze, turn signals, or gait features (for legged robots) to disambiguate navigation intentions, or adding voice to signal the urgency of the robot's navigation task.Gallery
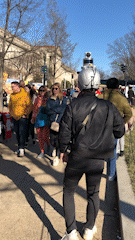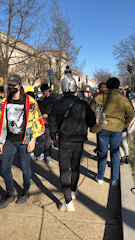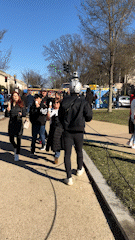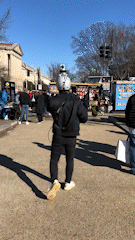



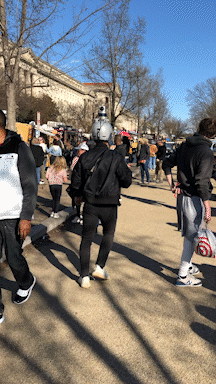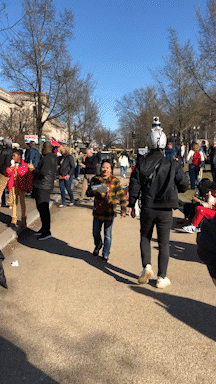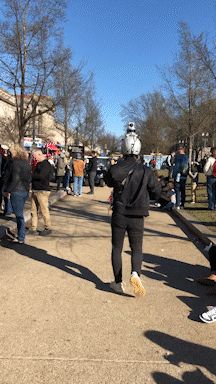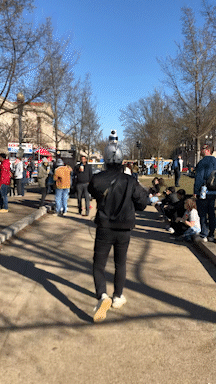

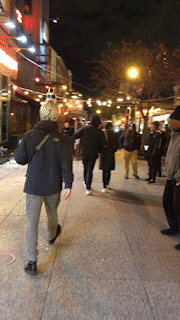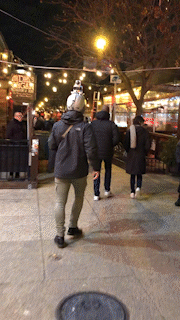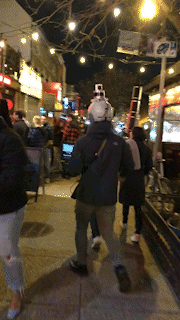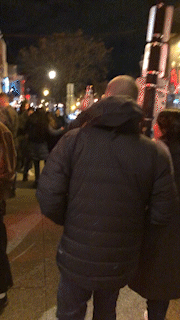












Links
Contact
For questions, please contact:
Dr. Xuesu Xiao
Department of Computer Science
George Mason University
4400 University Drive MSN 4A5, Fairfax, VA 22030 USA
xiao@gmu.edu